목차
1. 공부한 바에 의하면요..
2. 지금까지 GraphQL을 RESTful하게 쓰고 있었어요
- 네이밍도 GraphQL스럽게
- Single Query Pattern (같은 Node 타입에 여러 쿼리를 쓰고 있진 않나요)
3. GraphQL의 데이터는 '그래프'이다 (Resolver Chaining, Field-based 설계)
4. GraphQL 프로젝트 중간 회고
5. 마치면서
1. 공부한 바에 의하면요..
며칠 전에 유튜브를 돌아다니다가 영상을 하나 발견했다. Apollo Client의 maintainer로 일하고 있는 Lenz와의 인터뷰 영상이었는데, 여기서 원래 Apollo Client에 Suspense 기능이 도입된 설명을 들으려고 했다. 그런데 영상 초반에 GraphQL에 대해 간단히 설명하는 부분에서, 인터뷰어가 대규모 프로젝트에서 GraphQL의 등장이 얼마나 놀라웠는지 설명하는 부분이 흥미로워서 간단히 정리해보는 것으로 글을 시작하려고 한다.
인터뷰어는 2015년쯤에 IBM에서 일할 당시 GraphQL을 처음 접했다고 한다. 대기업 안에서 수많은 팀이 서로 다른 데이터를 관리하면서 각 팀의 시스템이 REST API를 통해 서로 통신해야 했다. 단순해 보이지만, 실제로는 많은 문제가 있었다.
1.1. 대규모 협업에서 REST API의 한계
일관성 부족
REST API는 팀마다 고유의 엔드포인트를 생성하고, 요청에 따라 특정 데이터를 반환한다. 하지만 서로 다른 팀의 API가 어떻게 데이터를 제공할지, 어떤 형식으로 반환할지 명확한 보장은 없다. 결국 데이터를 사용하는 쪽에서 이를 정리하고 통합하는 데 많은 코드를 작성해야 한다.
Single Source of Truth의 부재
각 팀이 요청에 맞춰 customize된 엔드포인트를 계속 만들어내다 보니, 데이터가 여러 엔드포인트에 중복되는 일이 많아졌다. 데이터를 신뢰할 수 있는 single source로 관리하는 개념이 없었기 때문에, 다른 팀의 변경 사항을 따라잡기 위해 계속해서 의사소통하는 방법밖엔 없었다.
의사소통 비용이 너무 지나침
모든 팀이 데이터 변경 사항을 실시간으로 공유하고, 필요하면 각자 새로운 엔드포인트를 만들어야 했다. 이게 개발 생산성을 크게 저해시키는 요소였다. "I think that's a really big challenge in code because codebases are too big for everybody to keep full context"
비효율적인 엔드포인트 관리
팀 간 의사소통을 줄이기 위해서, 각 팀은 요청된 데이터에 따라 새로운 커스텀 엔드포인트를 만들어서 제공했다.
FE: "이 데이터가 필요해요!"
BE: "엔드포인트 만들어드릴게요"
이렇게 생성된 엔드포인트는 중복이 많았고, 엔드포인트마다 관리해야 할 로직이 늘어났고, 이로 인해 전체적인 일관성을 유지하기는 점점 더 어려워졌다.
1.2. GraphQL의 등장
GraphQL은 이런 문제를 필요한 데이터를 명확히 정의하고, 필요한 만큼만 가져올 수 있도록 함으로써 해결했다. REST API와는 다르게, GraphQL에서는 클라이언트가 데이터를 요청하는 쿼리 형태를 정의한다.
query GetUser {
user(id: "123") {
name
email
posts {
title
}
}
}
GraphQL을 처음 접한 사람이어도 위의 쿼리문을 보면, '아~ name, email, posts의 title들만 필요하구나!'하고 바로 알아차릴 수 있다. REST와 달리 더 이상 불필요한 데이터를 가져오거나 새 엔드포인트를 만들어야 할 이유가 없다.
1.3. 장점
데이터 요청이 유연하다
REST API는 데이터 반환 형태가 정해져 있지만, GraphQL은 클라이언트가 원하는 데이터만 선택적으로 요청할 수 있다.
스키마 기반 설계
GraphQL은 스키마를 기반으로 API의 데이터 구조와 관계를 명확하게 정의한다. 이를 통해 팀 간에 필요한 정보만 공유하면 된다. 예를 들어, user data를 관리하는 팀은 "User 타입에 ID가 있다"라는 정보만 제공하면 된다. 그 외의 내부 구현은 다른 팀이 알 필요가 없고, 필요한 경우에만 커뮤니케이션하면 된다. API 문서화가 불필요할 정도로 클라이언트는 스키마를 통해 데이터 구조를 바로 이해할 수 있다.
API 사용량 분석이 가능하다
GraphQL은 필드 단위로 데이터를 요청하기 때문에 어떤 필드가 자주 사용되는지 분석할 수 있다. 만약 어떤 필드가 비용이 많이 드는데 아무도 호출하지 않는다면, 맘 편히 deprecate시킬 수 있다.
캐싱과 데이터 integrity가 용이하다
데이터 요청의 형태가 명확히 정의되기 때문에, 캐싱과 데이터 integrity 관리가 간편하다.
예를 들어 Apollo client는 동일한 데이터가 호출되면 자동으로 중복을 제거함으로써 성능을 최적화한다. 또한 REST에서도 데이터 변경 후 변경된 데이터를 반환할 수 있지만, 일반적으로 최신 상태를 유지하려면 별도의 refetch 요청을 보내야 하는 경우가 많다. 반면 GraphQL Mutation은 변경 결과를 명확히 반환하도록 설계되어 있기 때문에, 클라이언트에서 이 데이터를 받아 캐시에 병합함으로써 추가적인 refetch 없이 데이터를 최신 상태로 유지할 수 있다.
2. 지금까지 GraphQL을 RESTful하게 쓰고 있었어요
2.1. 네이밍도 GraphQL스럽게
GraphQL을 사용하면서 처음에는 RESTful한 사고방식에서 완전히 벗어나지 못했다는 걸 깨달았다. 특히 네이밍과 구조에서 REST API의 느낌이 강했다. 이후 리팩토링을 진행했는데, 전과 후를 비교해 보자.
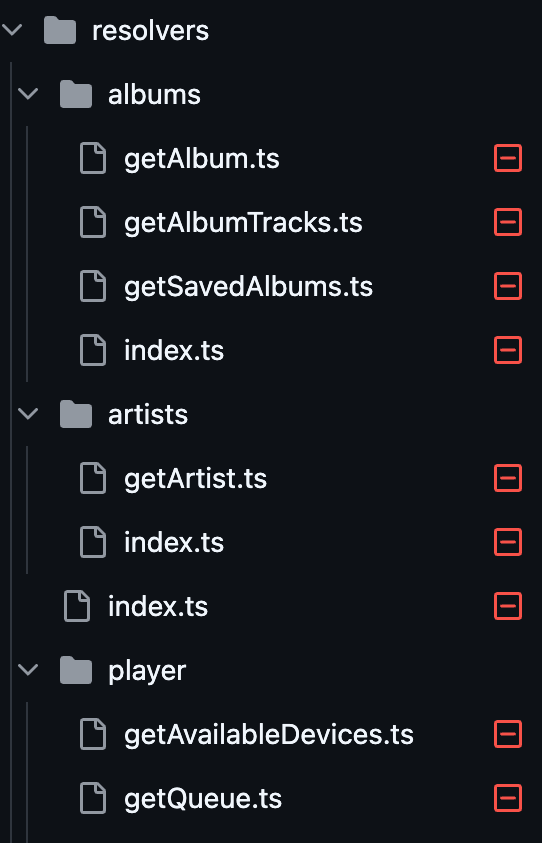

이 구조를 보면, 각 쿼리 이름이 REST의 엔드포인트 이름처럼 보인다. getAlbum이나 getAlbumTracks처럼 'get'이라는 동사를 사용해서 데이터를 가져오는 작업에 집중했다. 특정 리소스를 반환하는 REST API 엔드포인트와 비슷한 구조이다. 하지만 GraphQL은 그래프 기반으로 설계된 언어이고, REST와는 근본적으로 다르다는 것을 인지해야 한다.
그래프는 Node와 Edge로 구성된다. 여기서 Node는 Album, Track 등의 데이터를 나타내고, Edge는 노드 간의 관계를 나타낸다 (Album ↔ Tracks). 따라서 GraphQL을 설계할 때 이 그래프 구조를 반영해야 한다. "무엇을 가져올 것인가?"에 집중하면 안 되고, "어떤 노드와 관계를 탐색할 것인가?"에 초점을 맞춰야 한다.

getAlbum, getSavedAlbums를 album, savedAlbums로, 노드라는 것을 표현하는 형식으로 변경했다.
GraphQL 쿼리는 단순히 데이터를 가져오는 것이 아니라, 노드 간의 관계를 탐색할 수 있다. 예를 들어,
query {
album(albumId: "123") {
title
release_date
tracks {
title
duration
artist {
name
}
}
}
}
위 쿼리는 'album'이라는 노드에서 시작해 앨범의 정보, 트랙 노드, 트랙의 아티스트 노드로 그래프를 따라 이동한다. 이런 식으로 데이터의 연결 관계가 직관적으로 표현되는 것이다.
RESTful 접근 방식에서는 각 엔드포인트를 호출해야 했기 때문에 관계를 탐색하기에는 어렵고 비효율적이다. ex) GET /albums/123, GET /albums/123/tracks, GET /artists/:artistId,...
2.2. Single Query Pattern (같은 Node 타입에 여러 쿼리를 쓰고 있진 않나요)
예를 들어 다음과 같이 쿼리를 작성하고 있진 않았나 돌아보자.
type Query {
getUserById(userId: String!): User
getUserByName(userName: String!): User
}이렇게 작성하면, 같은 User Node에 대해 ID로 조회하거나 이름으로 조회하는 두 개의 쿼리를 작성하게 된다. GraphQL을 RESTful하게 사용하는 대표적인 사례라고 할 수 있다. 이게 어떤 문제가 있냐 하면,
- Node 중심의 설계가 아니다.
- 로직이 중복됐다: 쿼리가 많아질수록 서버에서 각 쿼리를 처리하기 위한 resolver 코드가 중복될 가능성이 크다.
- 확장성이 부족하다: 동일한 Node에 대해 또 다른 필터 조건으로 데이터를 조회하려면 추가 쿼리를 계속 생성해야 한다.
대신에 이렇게 작성해 보자.
type Query {
user(id: String, name: String): User
}이렇게 user라는 단일 쿼리로 통합하고, 필요한 경우 필터 조건을 인자로 전달하도록 설계하면 위의 문제점이 모두 해결된다. 다른 조건으로 검색하고 싶을 때도 동일한 user 쿼리에 조건만 추가하면 된다.
// id로 검색
query {
user(id: "123") {
name
email
}
}
// 이름으로 검색
query {
user(name: "Alice") {
id
email
}
}REST에서는 GET /users/:id와 GET /users?name=Alice처럼 여러 엔드포인트를 만들어야 하는 것과 비교했을 때, GraphQL에서는 단일 user 쿼리로 모든 요청을 처리할 수 있다.
3. GraphQL의 데이터는 '그래프'이다 (Resolver Chaining, Field-based 설계)
Resolver Chaining은 resolver가 서로 연결되어 작동하면서 한 resolver의 결과가 다음 resolver의 입력으로 사용되는 방식을 말한다. 예를 들어 player resolver가 currentTrack 필드를 반환하고, currentTrack resolver가 lyrics 필드를 반환하도록 연결된 구성이다.
type Query {
player: PlayerState
}
type PlayerState {
currentTrack: CurrentTrack
queue: [PlayerTrack]!
}
type CurrentTrack {
id: String
name: String
album: PlayerAlbum
artists: [PlayerArtist]
duration_ms: Int
lyrics: Lyrics
}
type Lyrics {
id: String
plainLyrics: String
syncedLyrics: String
}
Resolver Chaining 연결 흐름
1. player 쿼리:
player resolver는 Spotify API에서 현재 재생 중인 트랙(currently_playing)과 대기열(queue) 데이터를 가져온다. 가져온 데이터를 정리해서 PlayerState로 반환하여, currentTrack 필드는 CurrentTrack 타입으로 매핑된다.
const playerResolvers = {
Query: {
player: async (_: unknown, __: unknown, context: MyContext) => {
const data = await context.spotifyAxios.get(`/me/player/queue`);
return {
currentTrack: mapTrack(data.currently_playing),
queue: (data.queue || []).map(mapTrack),
};
},
},
};
2. lyrics 필드 탐색:
player resolver가 반환한 currentTrack 데이터는 CurrentTrack resolver로 전달된다. lyrics 필드가 요청되면, CurrentTrack resolver는 가사 데이터를 가져오고, 이게 Lyrics 타입으로 반환된다.
const playerResolvers = {
CurrentTrack: {
lyrics: async (parent: any) => {
const lyricsParams = {// ...}
const lyricsResponse = await lyricsAxios.get("/get", { params: lyricsParams });
return {
data: {
id: lyricsResponse.id || null,
plainLyrics: lyricsResponse.plainLyrics || "",
syncedLyrics: lyricsResponse.syncedLyrics || "",
},
};
},
},
};
이렇게 스키마에서 각 필드는 독립적으로 리졸버를 가지며, 클라이언트 요청에 따라 필요한 데이터만 반환하도록 설계된다.
이렇게 하면 뭐가 좋을까
1. 불필요한 데이터는 처리하지 않는다
- GraphQL 구조는 클라이언트가 요청한 필드만 리졸버를 호출하도록 설계되어 있다.
- 예를 들어, 클라이언트에서 lyrics 필드를 요청하지 않으면, CurrentTrack의 lyrics 리졸버는 실행되지 않는다.
- 이를 통해 리소스 사용을 절약하고 성능을 최적화할 수 있다.
2. 데이터 요청이 유연하다
- 클라이언트는 필요한 데이터만 요청할 수 있다.
- 예를 들어, 가사가 필요 없을 때는 lyrics 필드를 생략하면 된다.
- 이를 통해 네트워크 전송량을 줄이고, 클라이언트의 요구에 따라 데이터 요청을 유연하게 설계할 수 있도록 돕는다.
3. Resolver 관리가 독립적이다
- 각 필드는 독립적인 resolver로 관리되기 때문에, 특정 필드에 변경 사항이 생겨도 다른 필드에 영향을 미치지 않는다.
- 유지보수성과 확장성에 큰 도움이 된다.
4. 데이터 연결이 직관적이다
- GraphQL에서는 데이터의 관계와 흐름이 쿼리와 스키마에 명확히 표현된다.
- 예를 들어, player → currentTrack → lyrics로 이어지는 구조가 데이터 간의 연결 관계를 직관적으로 보여준다.
- GraphQL의 철학인 그래프 기반 데이터 탐색을 잘 드러낸다.
4. GraphQL 프로젝트 중간 회고
4.1. 지금까지의 고민
아직은 프로젝트에서 다루고 있는 데이터 양이 많지 않아 GraphQL의 장점이 크게 체감되지는 않는 것 같다. Resolver chaining, field-based 설계 등 GraphQL의 다양한 개념을 적용해보았지만, 그 효과가 뚜렷하게 와닿지는 않는다. 공부가 부족한 탓일지도 모른다.
예를 들어서 내가 생각하는 기술을 적용하는 이상적인 flow를 생각해보면,
1. 애플리케이션 속도가 느리다
2. 왜 느릴까? → 불필요한 데이터 요청이 많다
3. Resolver chaining으로 resolver를 분리하자
4. 불필요한 요청이 사라지고 성능이 개선되었다!
이건데, 현재 나의 flow는 다음과 같다.
1. GraphQL을 효율적으로 사용하고 싶다
2. Resolver chaining이라는 개념을 발견했다
3. 내 프로젝트에 적용해볼 곳이 없을까?
4. 적용해보긴 했지만, 지금은 효과가 잘 느껴지지 않는다
이런 흐름이 문제 해결 중심이 아닌 기술 적용 중심이라는 점에서, 아직 GraphQL을 활용하는 깊이가 부족하다고 느껴진다.
4.2. 큰 프로젝트일수록 GraphQL의 진가가 발휘된다
지금까지 GraphQL을 공부하면서 느낀 점은, GraphQL은 단순히 API를 대체하는 기술이 아니라 데이터 탐색과 관계를 중심으로 설계된 철학이라는 점이다. 그래서 GraphQL은 프로젝트 규모가 커질수록, 다루는 데이터가 복잡해질수록 진가가 발휘되는 기술이다. 현재 프로젝트는 상대적으로 데이터 구조가 간단하고, 적은 데이터 양을 다루고 있다. 여러 팀이 데이터를 협력적으로 관리해야 하는 경우, 데이터의 관계가 복잡하고, 쿼리가 다양한 조건으로 요청되는 경우, 또는 성능 최적화가 중요한 대량의 데이터 요청을 처리하는 경우에 유용할 것 같은데, 나는 토이프로젝트이다 보니 이게 잘 느껴지지 않는 것 같기도 하다.
4.3. 방향성
1. 문제 해결 중심으로 GraphQL 사용하기
기술을 적용하는 것에 그치지 않고, 문제를 해결하는 데에 활용하고 싶다. 예를 들어
- 데이터 요청에 중복이 많다 → Fragment를 사용해 해결
- 여러 팀이 같은 데이터를 관리한다 → Federation으로 독립적으로 협력 가능하게 만들기
2. 현재 프로젝트에서 적용해볼 기술들
TypeScript와 어떻게 결합할지 고민 중에 있다. Custom hook을 사용하는 방법은 RSC에서 사용하지 못하므로 고민이 되고, GraphQL code generator라는 것도 있던데 좀 더 알아볼 예정이다. 고민을 충분히 해서 GraphQL과 TypeScript를 통합한 나만의 Best Practice를 만들어보고 싶다.
3. 대규모 협업 프로젝트, 실무에서 느껴보고 싶은 GraphQL의 장점들
GraphQL의 진가를 제대로 느끼기 위해 여러 팀과 협업하는 대규모 프로젝트를 경험해보고 싶다. 특히,
- 각 팀이 데이터를 독립적으로 관리하고, 이를 Federation으로 통합하기
- 팀 간 스키마 설계와 통합 과정 경험하기
- 복잡한 데이터를 효율적으로 관리하기 위한 캐싱 전략 설계하기
5. 마치면서
GraphQL은 단순히 데이터를 요청하고 응답하는 기술이 아니라, 데이터를 탐색하고 관계를 설계하는 철학에 가깝다고 생각이 된다. 그렇기 때문에 프로젝트의 규모와 복잡성에 따라서 그 진가가 다르게 느겨질 수밖에 없다고 생각한다. 최근 며칠간은 정말 이 블로그 제목대로 GraphQL을 효율적으로 프로젝트에 녹여내기 위해 몸부림쳤다고 해도 과언이 아닐 것 같다. 작은 토이 프로젝트에서 당장은 모든 기능이 체감되진 않지만, 이 설계 철학을 배우려고 시도했던 과정 하나하나가 나중에 더 큰 프로젝트, 큰 기업에서 유의미한 역할을 할 것이라고 생각한다.
조만간 완성될 프로젝트도 기대해주세요!
'Projects,Activity > Spotify' 카테고리의 다른 글
| Optimization(1): Throttle & Debounce (4) | 2024.12.05 |
|---|---|
| Apollo client의 캐시가 Next.js를 만나면: SSR, RSC + Next.js 15의 바뀐점 (2) | 2024.12.04 |
| 쿠키가 도착하지 않는 이유- Express, Next.js, Browser 간 쿠키 전달 (1) | 2024.11.19 |
| Spotify API와 자체 DB를 통합한 인증 시스템 - JWT+JWT vs Session+JWT (0) | 2024.11.06 |



