목차
- Short Review- 1:1 통신
- 그럼 다대다 화상회의는?
- Kurento
- Openvidu
- 디스코드 클론코딩
1. Short Review - 1:1 통신
지난번엔 WebRTC로 1:1 화상회의가 구현되는 flow를 정리해 봤다. 간단하게 복습해 보자.
WebRTC: 화상 회의를 구현하는 방법
목차- 프롤로그- WebRTC의 동작 원리- Signaling Flow - 마치면서 1. 프롤로그채팅을 구현하기 위해서는 지속적인 연결을 유지하는 웹소켓을 사용한다. 웹소켓에서는 A가 B에게 채팅을 보낼 때 두 사
hwanheejung.tistory.com
1.1. 연결이 수립되기까지의 Flow
크게 SDP Offer/Answer 과정과 ICE Candidate 교환 과정으로 나눌 수 있다. 이 두 과정은 독립적, 병렬적으로 일어난다. 그러니까 SDP offer/answer 과정이 진행되는 동안에도 ICE candidate 정보를 교환해서 빠르게 P2P 연결이 수립된다.
- SDP Offer/Answer 과정 (미디어 정보 교환하자!)
① Peer A는 카메라, 마이크 상태와 같은 Media 정보를 등록
② 이 media 정보를 SDP에 담아 signaling server를 통해 Peer B에게 전달 - Offer
③ offer를 받은 Peer B는 마찬가지로 자신의 Media 정보를 Answer로 응답
- ICE Candidate 교환 과정 (너 누구야?)
① Peer A는 STUN 서버 또는 TURN 서버를 통해 자신의 IP 주소와 포트 정보를 알아낸 후, ICE candidate 객체에 포함시켜 signaling server를 통해 Peer B에게 전달
② Peer B도 마찬가지로 자신의 ICE candidate 정보를 signaling server를 통해 Peer A에게 전달
③ Peer A와 Peer B는 각각 받은 ICE candidate 정보를 이용하여 직접 연결을 시도
④ 연결 성공!

1.2. Signaling Server의 역할
브라우저끼리 통신을 하려면 서로 누군지 알아야 하는데, 그 과정을 signaling server가 중계해 주는 것이다. 즉, Signaling server는 단순히 offer, answer, 그리고 ICE candidate 정보를 교환하는 중계 역할만 하고 이 과정이 끝나면 더 이상 관여하지 않고 브라우저끼리 소통하게 된다.
2. 그럼 다대다 화상회의는?
#Mesh #SFU #MCU
2.1. Mesh
Zoom, Zep, 디스코드 등등 화상 기능을 제공하는 서비스들은 대부분 다대다 화상을 지원한다. 1:1 통신은 알겠는데 위에서 배운 방식대로 모든 참가자가 서로 직접 연결된다면(Mesh 방식) 몇십 명, 몇백 명 정도를 감당하기에는 무리가 있어 보인다. 간단하게 생각해 봐도, 4명이 화상회의를 한다고 했을 때, A-B, A-C, A-D, B-C, B-D, C-D, 즉 6번의 연결 수립이 이루어져야 한다. 참여자가 늘어날수록 연결의 수는 기하급수적으로 늘어나게 된다.
연결 수 = n(n-1)/2
즉, 다대다 통신을 P2P 통신으로 구현할 경우 클라이언트에 큰 부담이 될 것이다. 그래서 나온 것이 SFU, MCU 방식의 media server이다.
2.2. SFU (Selective forwarding Unit)
5명의 참가자가 있다고 했을 때, A는 자신의 영상 데이터를 B, C, D, E 모두에게 전송하는 게 아니라 media server에만 전송한다. Media server는 A의 데이터를 B, C, D, E에게 뿌린다. 즉, 1명당 1개의 uplink(클라->서버), 4개의 downlink(서버->클라)를 가지게 된다.

즉, 브라우저끼리의 P2P 연결이 아니라 서버-클라이언트 간의 peer 연결이다. Mesh 방식과 비교하면 downlink의 수는 n-1로 같지만 uplink의 수가 1개로 줄었다. 일부 참가자는 uplink가 필요 없을 수도 있다. 라이브 방송과 같이 publisher가 1명, subscriber가 N명인 1:N 통신인 경우, publisher는 영상 데이터를 media server에 한 번만 업로드하고 N명의 subscriber는 서버로부터 수신하는 경우 SFU를 사용하면 연결 수가 확실히 줄어든다. 또는 회의에서 발표하는 그룹과 듣는 그룹이 정해져 있는 경우와 같이 데이터를 송출하는 그룹(N명)과 수신하는 그룹(M명)이 명확하게 분리되어 있는 경우도 SFU 방식이 적합하다.
하지만 참가자가 엄청 많은 대규모 N:M 구조, 또는 N:N 통신의 경우에는 여전히 클라이언트가 많은 부하를 감당해야 할 수도 있는데, 이럴 땐 MCU 방식을 고려해 볼 만하다.
2.3. MCU (Multipoint Control Unit)
MCU에서는 media server가 모든 영상 데이터를 받아서 하나로 합치고, 이를 모든 클라이언트로 전송한다. 예를 들어 5명의 화상회의에서 중앙 서버는 A를 제외한 4명의 영상, 음성 데이터를 하나로 합쳐서 A에게 보낸다. 나머지 참가자들에게도 동일하게 적용되어 1명당 1개의 uplink, 1개의 downlink를 가지게 된다. 이 방식은 서버에 더 많은 부하를 주지만 클라이언트는 하나의 스트림만 전송, 수신하므로 부하가 확실히 줄어든다.
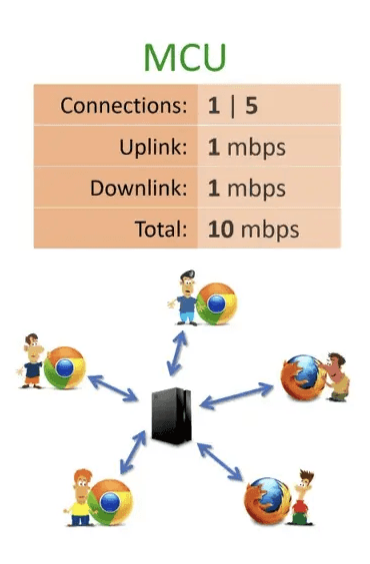
🤔 하지만 애초에 WebRTC가 나오게 된 이유가 서버의 부하를 줄이고 실시간성을 높이기 위함인데, MCU 방식은 일반적인 서버 기반 통신과 다를 게 없는 게 아닐까?
아니다. WebRTC의 MCU 방식에서도 서버에 부하가 걸리지만, 프로토콜 최적화와 QoS 관리, 그리고 보안 측면 덕분에 더 효율적으로 관리할 수 있다. 서버에 부하가 크긴 하지만, 그래도 WebRTC를 안 쓰는 것보단 쓰는 게 훨씬 효율적이라는 뜻이다.
- 프로토콜의 차이
WebRTC는 실시간 통신을 위해 설계된 protocol(SRTP, DTLS, ICE,...)을 사용한다. 이러한 protocol들은 실시간으로 데이터를 전송하고, 보안, NAT 및 방화벽 traversal 등을 효율적으로 처리한다. 일반적인 서버 기반 통신은 이러한 최적화가 부족해서 지연 시간이 더 길기 때문에 실시간성을 높이기 위해 추가적인 작업이 필요할 수 있다.
- QoS(서비스 품질)
WebRTC는 네트워크 상태에 따라 자동으로 해상도 등을 조정함으로써 품질을 높인다.
- 보안
WebRTC는 SRTP으로 암호화된 미디어 스트림을 사용하여 보안을 높인다.
2.4. Media Server가 하는 일
① Group Communications
위에서 설명한 것처럼 한 peer가 생성한 미디어 스트림을 여러 subscriber들에게 전달한다. SFU, MCU 역할을 하는 것이다.
② Mixing
여러 개로 들어오는 미디어 스트림을 하나의 스트림으로 합친다. 예를 들어 N명의 비디오 스트림을 하나의 화면에 합성해서 각 참가자가 N개의 비디오 화면을 동시에 볼 수 있게 하고, 여러 참가자의 목소리를 하나의 오디오 스트림으로 mixing 해서 동시에 들을 수 있게 하는 것을 말한다.
③ Transcoding
클라이언트 간에 호환이 되지 않을 때, codec과 format을 실시간으로 변환하는 작업을 한다. 예를 들어 한 클라이언트가 H.264 비디오 codec을 사용하고 다른 클라이언트가 VP8 비디오 codec을 사용한다면, 서버는 H.264 스트림을 VP8로 변환하여 호환성을 유지하게 된다.
④ Recording
클라이언트 간에 교환되는 미디어를 저장한다. 예를 들어 회의를 녹화해서 나중에 또 볼 수 있도록 할 수 있다.
3. Kurento
Kurento는 media server의 일종으로 일단 무료이고, docs가 정말 자세하다. MCU, SFU 모두 지원하며, 클라이언트 API를 제공한다.
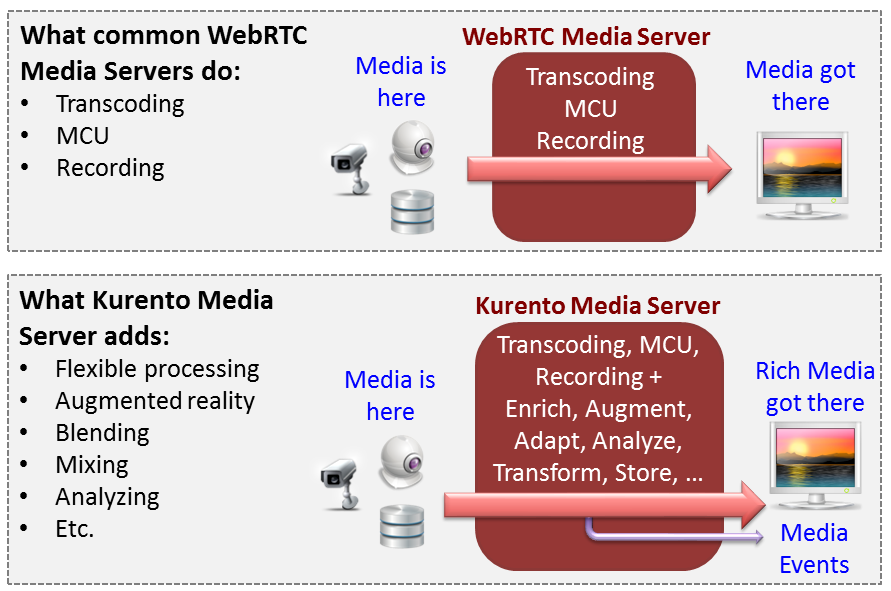
https://doc-kurento.readthedocs.io/en/latest/user/intro.html#why-a-webrtc-media-server
자세한 내용은 kurento 공식 문서에 설명되어 있지만, 개발하는 입장에서 와닿는 장점을 몇 가지 소개하자면 다음과 같다.
Distribution of Media and Application Services
Kurento Media Server(KMS)는 여러 기기에서 배포, 확장, 분산될 수 있다. 하나의 애플리케이션이 여러 KMS를 호출할 수 있고, 반대로 하나의 KMS도 여러 애플리케이션의 요청을 처리할 수 있다.
Application development
개발자는 복잡한 KMS 내부를 신경 쓰지 않아도 된다. 모든 프레임워크에서 배포 가능하다.
End-to-End Communication Capability
Kurento는 미디어의 전송, encoding/decoding 및 클라이언트 장치에서의 렌더링 복잡성을 처리하지 않아도 되는 end-to-end 통신을 제공한다.
그러니까 개발자들이 WebRTC 기반의 SFU, MCU를 low level에서 개발하지 않아도 kurento를 사용해서 어느 정도 쉽게 구현할 수 있고, 추가적으로 다양한 기능들도 많이 지원한다.
그런데 kurento docs에 눈에 띄는 경고문이 있다.

초짜면 Openvidu를 써라.
4. OpenVidu
OpenVidu는 Kurento 기반의 프레임워크이다. WebRTC를 사용하는 경우는 보통 화상 회의를 구현해야 하는 경우일 텐데, 간단한 화상 회의를 개발하는데 굳이 kurento의 low level 코드를 만지지 않아도 된다. 복잡한 기능을 개발해야 한다면 kurento를 써도 되는데, openvidu로도 충분히 많은 기능을 구현할 수 있기 때문에 kurento 공식페이지에서도 openvidu를 적극적으로 추천하고 있다.
OpenVidu 페이지로 가봤더니 v3.0.0에 엄청난 변화가 생겼다. 내부 media server로 kurento를 버리고 mediasoup를 선택했고, livekit가 도입됐다. 하지만 문제는 Mediasoup는 node.js 환경에서 사용되도록 설계되었는데 우리는 spring을 사용하고 있다. 통합을 시도해 봤지만 쉽지 않았고, 그래서 kurento 기반의 v2.30.0 버전을 쓰기로 했다.
kurento도 그렇고 openvidu도 그렇고 문서가 너무너무 자세하고 친절하다. 프레임워크별 튜토리얼까지 하나하나 설명해놓은 문서는 처음이다..

어쨌든! 간단한 구현은 튜토리얼 보고 하면 된다(class 컴포넌트로 설명해서 함수형으로 바꿔야 하는 문제가 있긴 하다). 하지만 우리는.. 무려 디스코드 클론코딩이기에.. 단순히 코드 복붙으로 될 일이 아니었다.
5. 디스코드 클론코딩
프로젝트 요구사항
1. OpenVidu tutorial은 class component로 설명되어 있지만, 이를 함수형으로 변경하고 typescript를 적용시켜야 함.
2. 화상 회의 채널은 여러 개 생성할 수 있음. (채널을 생성할 때 타입을 선택하는 방식. 채팅, 화상 중 선택)
3. 화상회의를 하는 도중 화면을 이탈하고 다른 채널에 들어가도 화상 연결이 끊기면 안됨
4. 화상회의를 하는 도중 다른 화상채널에 들어가는 경우, 기존의 연결을 끊고 들어가야 함
5. video, audio on/off
6. 화면공유
7. 참가자를 클릭하면 크게 보여야 함 (mainStreamManager)
참고) 코드가 너무 길어져서 custom hook으로 분리했고, 상태들은 zustand로 전역에서 관리했다.
+ 코드가 궁금하신 분들을 위해 깃허브 링크 걸어두겠습니다
zustand: https://github.com/DizzyCode2024/client/tree/main/src/lib/stores/voice
hooks: https://github.com/DizzyCode2024/client/tree/main/src/lib/hooks/voice
components: https://github.com/DizzyCode2024/client/tree/main/src/components/voice
5.1. Join Session 플로우 간략하게 정리
세션 참가 플로우가 살짝 복잡해서 간단하게 순서를 정리해 두겠다.
1. sessionId 받기 - mySessionId를 서버에 전송
const createSession = async (mySessionId: string) => {
try {
const response = await axiosInstance.post(`/api/sessions`, {
customSessionId: mySessionId,
});
return response.data; // sessionId
} catch (e) {
console.log('ERROR AT CREATING SESSION', e);
return null;
}
};
2. token 받기
const createToken = async (sessionId: any) => {
try {
const response = await axiosInstance.post(
`/api/sessions/${sessionId}/connections`,
{},
);
return response.data; // token
} catch (e) {
console.log('ERROR AT CREATING TOKEN', e);
return null;
}
};const getToken = async () => {
const sessionId = await createSession(mySessionId.toString());
const token = await createToken(sessionId);
return token;
};
3. token으로 session 연결 시도
4. getUserMedia
5. publish
https://github.com/DizzyCode2024/client/blob/main/src/lib/hooks/voice/useVoiceRoom.ts
Reference
- https://doc-kurento.readthedocs.io/en/latest/user/intro.html#why-a-webrtc-media-server
- https://openvidu.io/latest/docs/tutorials/application-client/react/
- https://millo-l.github.io/WebRTC-%EA%B5%AC%ED%98%84-%EB%B0%A9%EC%8B%9D-Mesh-SFU-MCU/
- https://github.com/OpenVidu/openvidu/issues/60
GitHub - DizzyCode2024/client: DizzyCode Client - Discord Clone Project
DizzyCode Client - Discord Clone Project. Contribute to DizzyCode2024/client development by creating an account on GitHub.
github.com
'Projects,Activity > DizzyCode(React)' 카테고리의 다른 글
| [WebSocket] 비정상 종료 핸들링 전략 (1) | 2024.07.31 |
|---|---|
| [WebRTC] 화상 회의를 구현하는 방법 (1:1) (2) | 2024.07.05 |
| [DizzyCode] 디스코드 클론코딩, 시작! (7) | 2024.07.02 |
| [DizzyCode] WebSocket+JWT 시나리오 (1) | 2024.05.29 |
| WebSocket+STOMP: 개념 이해부터 구현까지 (0) | 2024.05.29 |



